Computing Power and Data Needed for AI
@moxie notes that LLMs make the 90% of the solution easy to build, but that last 10% is what takes the time. Fine-tuning can take you most of the rest of the way, but getting it perfect is an open-ended problem. A non-LLM app, by contrast, is more difficult to prototype but much easier to test. He concludes:
I do not understand how the economics of LLMs pencil out. When I look at the per concurrent user costs associated with inference, they seem orders of magnitude higher than per concurrent user costs of previous internet technologies. It seems to me that if previous apps like webmail, messengers, etc had costs as high, they would not have been viable products. This is something I want to learn more about.
Brave browser developer Brendan Eich is betting on smaller, custom models partly for that reason and because inference costs a ton more for the bigger commercial models. If you’re going to take the effort to get it to be accurate, you might as well built your own, smaller model.
@mark_cummins estimates the total amount of text from every source
How much LLM training data is there, in the limit?
Firstly, here’s the size of some recent LLM training sets, with human language acquisition for scale:
| Training Set (Words) |
Training Set (Tokens) |
Relative size (Llama 3 = 1) |
|
| Recent LLMs | |||
| Llama 3 | 11 trillion | 15T | 1 |
| GTP-4 | 5 trillion | 6.5T | 0.5 |
| Humans | |||
| Human, age 5 | 30 million | 40 million | 10-6 |
| Human, age 20 | 150 million | 200 million | 10-5 |
And here’s my best estimate of how much useful text exists in the world:
| Words | Tokens | Relative size (Llama 3 = 1) |
|
| Web Data | |||
| FineWeb | 11 trillion | 15T | 1 |
| Non-English web data (high quality) | 13.5 trillion | 18T | 1 |
| Code | |||
| Public code | – | 0.78T | 0.05 |
| Private Code | – | 20T | 1.3 |
| Academic publications and patents | |||
| Academic articles | 800 billion | 1T | 0.07 |
| Patents | 150 billion | 0.2T | 0.01 |
| Books | |||
| Google Books | 3.6 trillion | 4.8T | 0.3 |
| Anna’s Archive (books) | 2.8 trillion | 3.9T | 0.25 |
| Every unique book | 16 trillion | 21T | 1.4 |
| Social media | |||
| Twitter / X | 8 trillion | 11T | 0.7 |
| 29 trillion | 38T | 2.5 | |
| 105 trillion | 140T | 10 | |
| Publicly available audio (transcribed) | |||
| YouTube | 5.2 trillion | 7T | 0.5 |
| TikTok | 3.7 trillion | 4.9T | 0.3 |
| All podcasts | 560 billion | 0.75T | 0.05 |
| Television archives | 50 billion | 0.07T | 10-3 |
| Radio archives | 500 billion | 0.6T | 0.04 |
| Private data | |||
| All stored instant messages | 500 trillion | 650T | 45 |
| All stored email | 900 trillion | 1200T | 80 |
| Total human communication | |||
| All human communication (daily) | 115 trillion | 150T | 10 |
| All human communication (since 1800) | 3 million trillion | 4000000T | 105 |
| All human communication (all time) | 6 million trillion | 8000000T | 105 |
At 15 trillion tokens, current LLM training sets seem close to using all available high-quality English text. Possibly you could get to 25 – 30T using less accessible sources (e.g. more books, transcribed audio, Twitter). Adding non-English data you might approach 60T. That seems like the upper limit.
When will data run out?
from WSJ
Pablo Villalobos, who studies artificial intelligence for research institute Epoch, estimated that GPT-4 was trained on as many as 12 trillion tokens. Based on a computer-science principle called the Chinchilla scaling laws, an AI system like GPT-5 would need 60 trillion to 100 trillion tokens of data if researchers continued to follow the current growth trajectory, Villalobos and other researchers have estimated.
Harnessing all the high-quality language and image data available could still leave a shortfall of 10 trillion to 20 trillion tokens or more, Villalobos said.
AI will run out of training data in 2026 says Villalobos et al. (2022)
Our analysis indicates that the stock of high-quality language data will be exhausted soon; likely before 2026. By contrast, the stock of low-quality language data and image data will be exhausted only much later; between 2030 and 2050 (for low-quality language) and between 2030 and 2060 (for images).
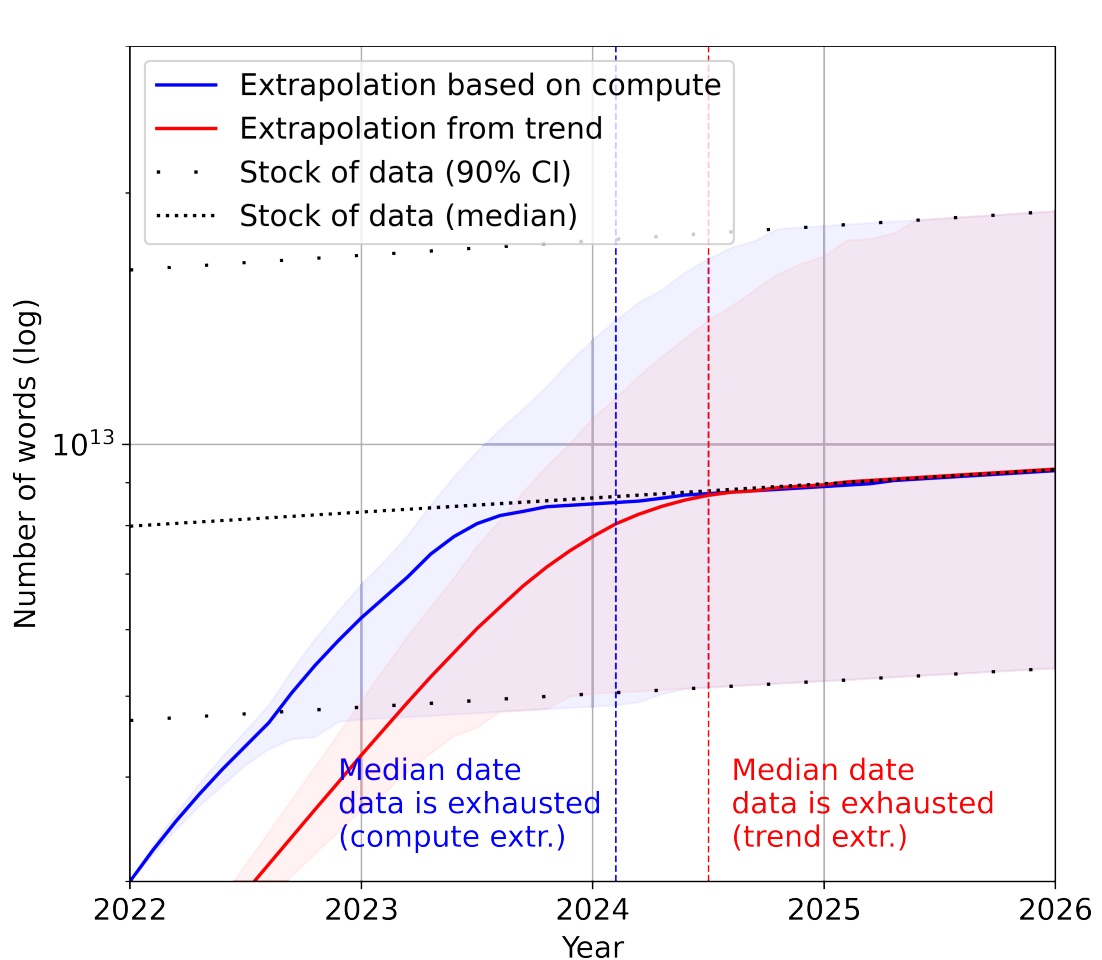 (“They have since become a bit more optimistic, and plan to update their estimate to 2028.”)
(“They have since become a bit more optimistic, and plan to update their estimate to 2028.”)
DatalogyAI is a data science startup that uses “curriculum learning”, a method involving carefully sequenced data ordering, that claims it can halve the data required.
and “Model Collapse” will severely degrade the quality of these models over time, greatly increasing the value of human-collected data. Shumailov et al. (2023) ***
Udandarao et al. (2024): “multimodal models require exponentially more data to achieve linear improvements”
Scaling limitations
Dwarkesh Patel asks “Will Scaling Work” and concludes:
So my tentative probabilities are: 70%: scaling + algorithmic progress + hardware advances will get us to AGI by 2040. 30%: the skeptic is right - LLMs and anything even roughly in that vein is fucked.
His post is a lengthy point-counter-point discussion with technical details that confronts the question of whether LLMs can continue to scale after they’ve absorbed all the important data.
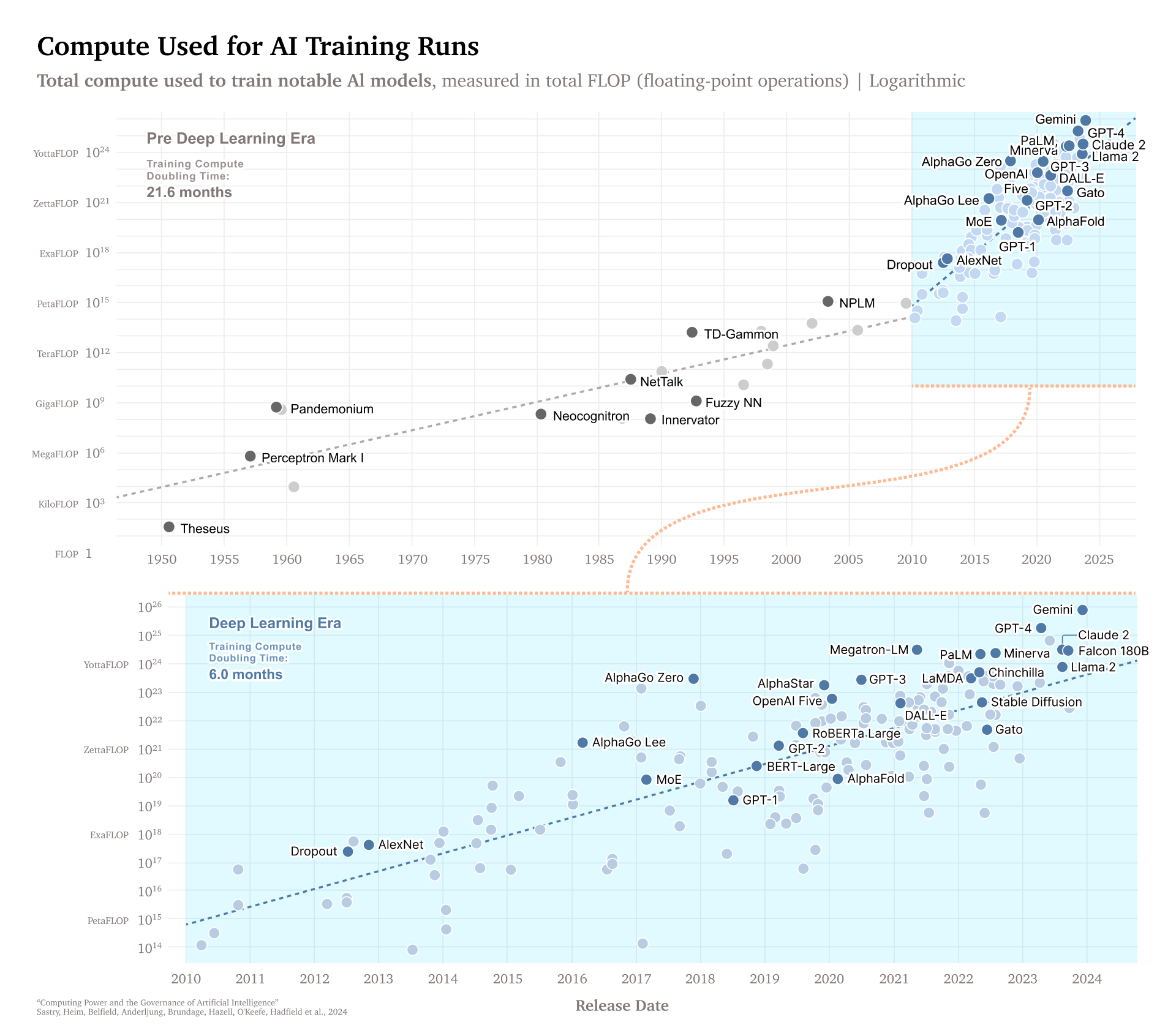
Meanwhile, to train LLM models keeps requiring more computing power (“compute”). Sastry et al. (2024) argue that this is a critical dependency that governments can exploit to regulate AI development.
Jason Wei (2024) Researchers at Meta have a detailed look at LLM scaling laws: Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
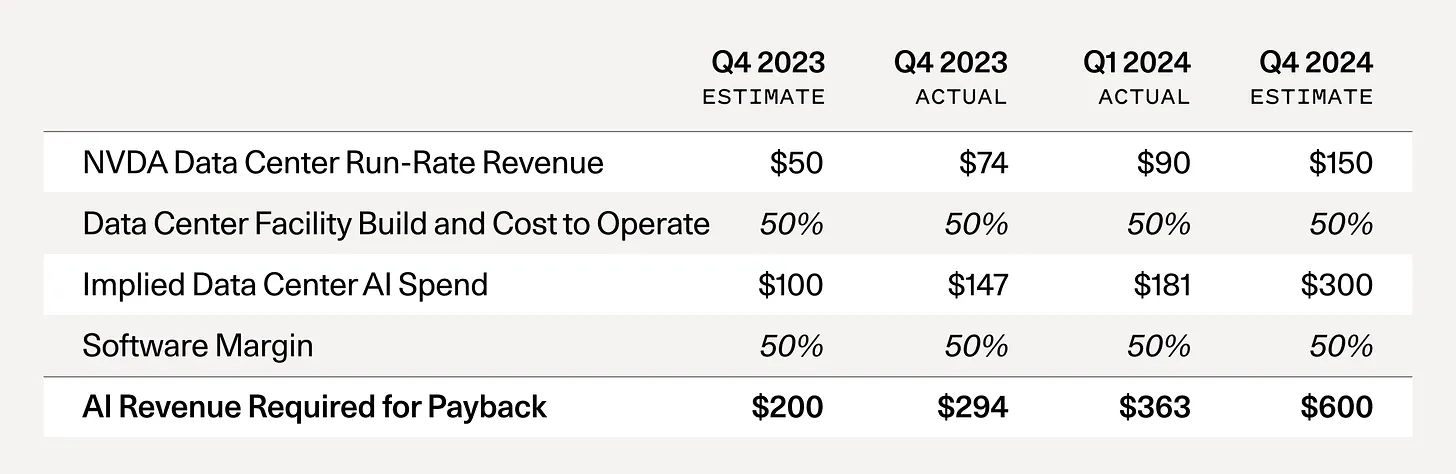
Sequoia Capital David Cahn (Jun 2024) asks AI’s $600B Question
“GPU capacity is getting overbuilt. Long-term, this is good. Short-term, things could get messy.”
AI Snake Oil recounts scaling myths:
Training compute, on the other hand, will probably continue to scale for the time being. Paradoxically, smaller models require more training to reach the same level of performance. So the downward pressure on model size is putting upward pressure on training compute. In effect, developers are trading off training cost and inference cost. The earlier crop of models such as GPT-3.5 and GPT-4 was under-trained in the sense that inference costs over the model’s lifetime are thought to dominate training cost. Ideally, the two should be roughly equal, given that it is always possible to trade off training cost for inference cost and vice versa. In a notable example of this trend, Llama 3 used 20 times as many training FLOPs for the 8 billion parameter model as the original Llama model did at roughly the same size (7 billion).
Hoffmann et al. (2022)
we find that for compute-optimal training, the model size and the number of training tokens should be scaled equally: for every doubling of model size the number of training tokens should also be doubled.
Maybe Data Doesn’t Matter?
Matt Rickard explains why data matters less than it used to:
A lot of focus on LLM improvement is on model and dataset size. There’s some early evidence that LLMs can be greatly influenced by the data quality they are trained with. WizardLM, TinyStories, and phi-1 are some examples. Likewise, RLHF datasets also matter.
On the other hand, ~100 data points is enough for significant improvement in fine-tuning for output format and custom style. LLM researchers at Databricks, Meta, Spark, and Audible did some empirical analysis on how much data is needed to fine-tune. This amount of data is easy to create or curate manually.
Model distillation is real and simple to do. You can use LLMs to generate synthetic data to train or fine-tune your own LLM, and some of the knowledge will transfer over. This is only an issue if you expose the raw LLM to a counterparty (not so much if used internally), but that means that any data that isn’t especially unique can be copied easily.
But the authors at Generating Conversation explain OpenAI is too cheap to beat. Some back-of-the-envelope calculations show that it costs their company 8-20x more to do a model themselves than to use the OpenAI API, thanks to economies of scale.