Limits of AI
Epoch AI “a research institute investigating key trends and questions that will shape the trajectory and governance of AI” produces some data-heavy analyses of where AI might be headed.
Epoch AI (2024)
the largest training run in 2027 will cost over $1 billion in compute expenses.
Epoch AI, ‘Data on Large-Scale AI Models’. Published online at epochai.org. Retrieved from https://epochai.org/data/large-scale-ai-models. Accessed 29 Aug 2024.
Scaling
Emergence
Some MIT researchers claim proof of emergent capabilities in language models trained on programs. Specifically, they claim their code-optimized Language Model was able to pull semantic meaning from source code alone. But I wonder if this “emergence” is really just a consequence of the ways human programmers wrote the code in the first place. Their model is able to “discover” an inner grid map of an LM trained only on the code that generates the grid. But isn’t that just because we humans’ idea of “interpret” is that grid map itself. In other words, “interpret” and “emergent” are the same thing.
Notes from Aurorean
[!NOTE]
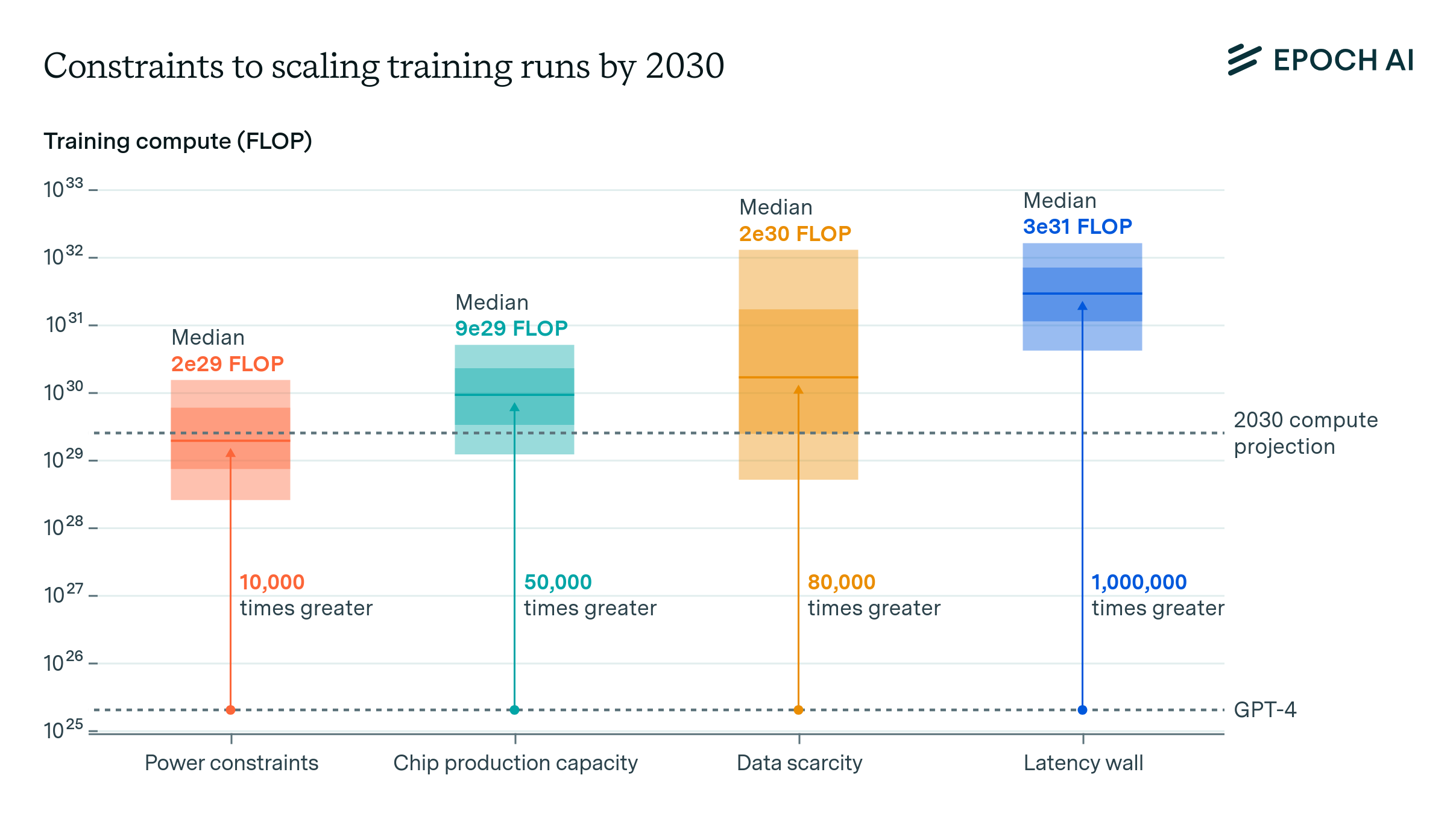
==AI Scaling Projections, Constraints & The Question of Emergence==Epoch AI researchers recently published a detailed report attempting to forecast the scale of AI models at the end of the decade. They focused their assessment on 3 potential bottlenecks that may limit progress over the next 5 years: scarcity of high-quality data, hardware chip production capacity, and available energy power. Their report details why these 3 pillars are constraints to scale and how they may be solved in due time. Ultimately, in spite of these challenges, the team estimates AI may scale by 10,000x from where we are today by 2030.
While this is a large, significant number, it is hard to appreciate what this actually means in terms of model performance without more context. Several researchers in the AI field are trying to understand what future models may be capable of by examining if there are predictable, logarithmic performance improvements observed with additional scale. For example, the Grokking paper by UC Berkeley researchers, the Mirage paper by Stanford researchers and Meta’s paper about Llama 3.1, all tackle this question, and their findings indicate high degrees of performance predictability. However, there is still the question of emergent capabilities, as noted by a team of MIT researchers, among many others.