AI and Coding
Technical details for how to use the latest AI tools
See Also
HN users thinkClaude 3 is slightly better for engineering but GPT-4 still is better at internet searching and code interpreter.
Calculate token costs with TokenCost
Convert your Git repo to text with RepoToTextForLLMs: Retrieves text contents from files, intelligently skipping over binary files to streamline the analysis process.
What I learned from looking at 900 most popular open source AI tools March 2024 Chip Huyen
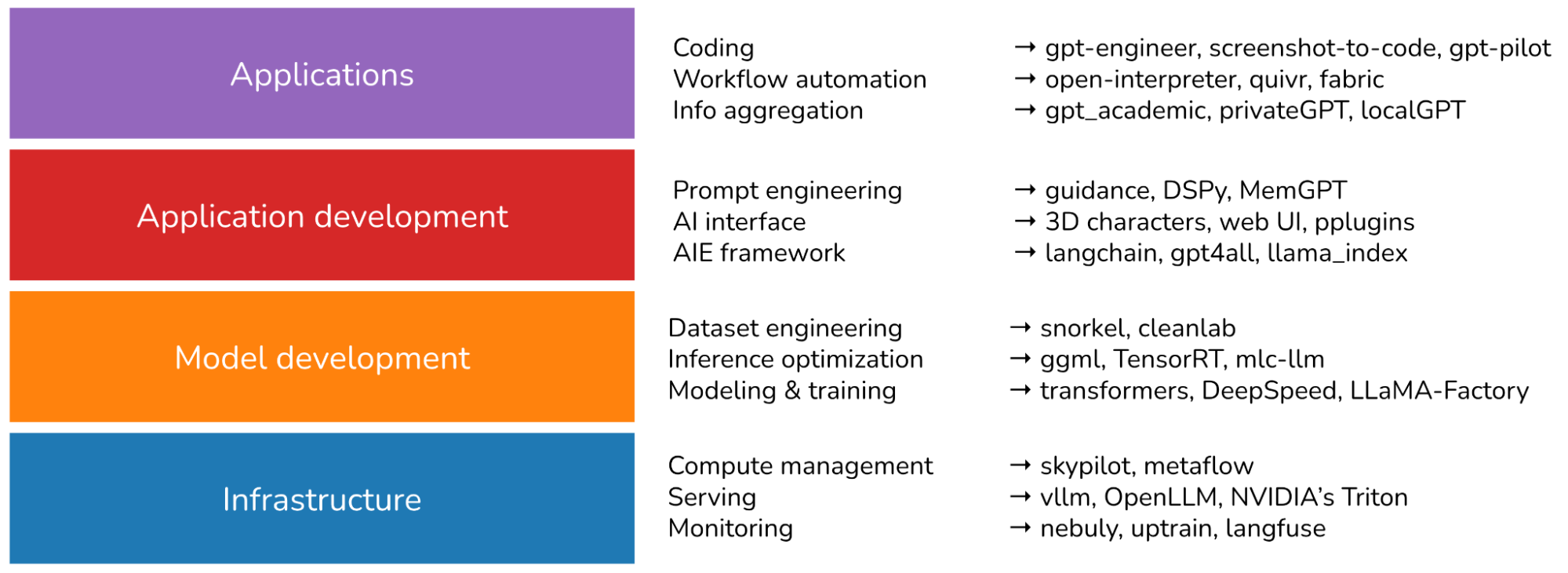
Lets Build AI a well laid-out collection of AI tools
AlphaCodium : a test-based, multi-stage, code-oriented iterative flow, that improves the performances of LLMs on code problems. See their blog entry

DeepEval is like PyTest only for LLM apps.
Switch from OpenAI to Open Source using PostgresML Switch Kit
import pgml
client = pgml.OpenSourceAI()
results = client.chat_completions_create(
"HuggingFaceH4/zephyr-7b-beta",
[
{
"role": "system",
"content": "You are a friendly chatbot who always responds in the style of a pirate",
},
{
"role": "user",
"content": "How many helicopters can a human eat in one sitting?",
},
],
temperature=0.85,
)
print(results)StarCoder is an Alternative to Code Pilot from HuggingFace and ServiceNow.
When slotting in language models to your code base, a useful mental model is treating them like functions with standard input and output. This blog, from the creator of React Native, shows a few ways you can do that and the benefits of modeling your models this way
const prompt = 'Build a chat app UI';
const components = llm<Array<string>>(
'You only have the following components: ' +
designSystem.getAllExistingComponents().join(', ') + '\n' +
'What components to do you need to do the following:\n' +
prompt
);
// ['List', 'Card', 'ProfilePicture', 'TextInput']
const result = llm<{javascript: string, css: string}>(
'You only have the following components: ' +
components.join(',') + '\n' +
'Here are examples of how to use them:\n' +
components.map(component =>
designSystem.getExamplesForComponent(component).join('\n')
).join('\n') + '\n' +
'Write code for making the following:\n' +
prompt
);
// { javascript: '...', css: '...' }Build LLM apps in the browser with Ollama. See Vercel implementation.
Magentic is a Python library that lets you incorporate an LLM easily into regular code.
from magentic import prompt
@prompt('Add more "dude"ness to: {phrase}')
def dudeify(phrase: str) -> str:
... # No function body as this is never executed
dudeify("Hello, how are you?")
# "Hey, dude! What's up? How's it going, my man?"Study a code repo with SolidGPT.

You specify what kind of app you want to build. Then, GPT Pilot asks clarifying questions, creates the product and technical requirements, sets up the environment, and starts coding the app step by step, like in real life, while you oversee the development process. It asks you to review each task it finishes or to help when it gets stuck. This way, GPT Pilot acts as a coder while you are a lead dev who reviews code and helps when needed.

YouAI lets you build custom apps with full-blown workflows, including chat interfaces, summarizers, analyzers, and document editors, plus trained with external data. (See )
ChatGPT-AutoExpert is a set of detailed prompts to get better code out of ChatGPT.
SudoLang is a programming language designed to collaborate with AI language models including ChatGPT, Bing Chat, Anthropic Claude, and Google Bard. It is designed to be easy to learn and use. It is also very expressive and powerful. A typical code sample includes a short natural language description, a few variable constructs, and a set of flags to change the output.
Stas Bekman’s Machine Learning Engineering Guides and Tools: An open collection of methodologies to help with successful training of large language models and multi-modal models.
Factory “Your Coding Droid”
Unlike existing products, Factory’s droids are hands-off – they can review code, address bugs and answer questions independently.
Poolside (via “The Generalist”)
OpenAI foundation-model approach but focusing on only one capability: code generation. Their technical strategy hinges on the fact that code can be executed, allowing for immediate and automatic feedback during the learning process.)
LLM is a command-line utility that lets you talk to OpenAI and other LLMs.
A CLI utility and Python library for interacting with Large Language Models, including OpenAI, PaLM and local models installed on your own machine.
OSSChat is Open Source chatbot
I tried it with “what libraries exist to help me study my freestyle libre cgm results?” and it returned a bunch of results, but no obvious way to link to the response.
Kaguya an open-sourced ChatGPT plugin that can access your filesystem to read and write python project files while you code.
Getting Started with Transformers and GPT
what StackOverflow thinks about ChatGPT
and an academic study showing a big drop in usage https://academic.oup.com/pnasnexus/article/3/9/pgae400/7754871?login=false
ToolLLM
[ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world API
Tool use is a paradigm where a language model produces words that trigger certain APIs to be called with the output being piped back in as tokens to the language model. This means that language models can use calculators, web browsers, and even coding environments. With the recent release of powerful open source language models, you can collect 40k+ viable APIs and fine-tune the model to use them. When you do this, you get a powerful Toolformer.
Sample Applications
See My Sample Apps for details of one that I built.
OpenAI: my experiments (Private details of my setup)
ShowHN: BBC “In Our Time”, categorised by Dewey Decimal, heavy lifting by GPT detailed breakdown of how one person built a sample application.
How to Develop
Exo is a way to distribute GPU power among multiple machines so you can run AI inference on your Mac, iPad, etc.
Step-by-step how to build an email to calendar LLM
Build a RAG-Based Digital Restaurant Menu with LlamaIndex and W&B Weave
Simon Willison shows a step-by-step deep dive into how he gets ChatGPT Code Interpreter to build a native C extension to SQLite. One trick, if it insists it can’t do something, is to ask it for the error message. You can also ask it to save intermediate steps to disk and send you the link.
A16Z published AI Companion App (based on AI Getting Started template)
This is a tutorial stack to create and host AI companions that you can chat with on a browser or text via SMS. It allows you to determine the personality and backstory of your companion, and uses a vector database with similarity search to retrieve and prompt so the conversations have more depth. It also provides some conversational memory by keeping the conversation in a queue and including it in the prompt.
How to build a ChatGPT + Google Drive app with LangChain and Python: “How to use ChatGPT with your Google Drive in 30 lines of Python.”
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
from langchain.document_loaders import GoogleDriveLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
folder_id = "YOUR_FOLDER_ID"
loader = GoogleDriveLoader(
folder_id=folder_id,
recursive=False
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=4000, chunk_overlap=0, separators=[" ", ",", "\n"]
)
texts = text_splitter.split_documents(docs)
embeddings = OpenAIEmbeddings()
db = Chroma.from_documents(texts, embeddings)
retriever = db.as_retriever()
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo")
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=retriever)
while True:
query = input("> ")
answer = qa.run(query)
print(answer)Playing with Streamlit and LLMs details of how to customize an LLM to answer questions about a blog.
A tweet thread from @matchaman11 on how to train a chatbot on a Notion database.
Build Your Own ChatBot with GPT-3 and Lenny Chatbot
Stanford Alpaca, “which aims to build and share an instruction-following LLaMA model” (and HN)
Seattle’s AI2 Incubator (Vu Ha) on Github keeps a sample AI2I_Webapp with docker and AWS deployment information
Build Your Own LLM
Together.ai is a cloud-based LLM customization company. See their excellent tutorials.
Use LLMs to judge quality of other LLM output
O’Reilly has a lengthy detailed list of tips on What We Learned from a Year of Building with LLMs (Part I). Use n-shot prompting (n>5), RAG is better than fine-tuning, Long-context models don’t make RAG obsolete, etc.
You can now train a 70b language model at home from Answer.ai, an open source system, based on FSDP and QLoRA, that can train a 70b model on two 24GB GPUs. With source code, including the script training.py
Building Large Language Models
GPT4All is a Github repo of open-source chatbots trained on a massive collections of clean assistant data including code, stories and dialogue
and a simple step-by-step tutorial of how to use it with LangChain
Karpathy’s NanoGPT is
The simplest, fastest repository for training/finetuning medium-sized GPTs. It is a rewrite of minGPT that prioritizes teeth over education. Still under active development, but currently the file train.py reproduces GPT-2 (124M) on OpenWebText, running on a single 8XA100 40GB node in about 4 days of training. The code itself is plain and readable: train.py is a ~300-line boilerplate training loop and model.py a ~300-line GPT model definition, which can optionally load the GPT-2 weights from OpenAI. That’s it.
via HN Discussion and more
Tools
Instructor (GitHub) a Python library that makes it a breeze to work with structured outputs from large language models (LLMs). Built on top of Pydantic, it provides a simple, transparent, and user-friendly API to manage validation, retries, and streaming responses.
import instructor
from pydantic import BaseModel
from openai import OpenAI
# Define your desired output structure
class UserInfo(BaseModel):
name: str
age: int
# Patch the OpenAI client
client = instructor.from_openai(OpenAI())
# Extract structured data from natural language
user_info = client.chat.completions.create(
model="gpt-3.5-turbo",
response_model=UserInfo,
messages=[{"role": "user", "content": "John Doe is 30 years old."}],
)
print(user_info.name)
#> John Doe
print(user_info.age)
#> 30YouAI lets you build custom apps with full-blown workflows, including chat interfaces, summarizers, analyzers, and document editors, plus trained with external data.
StartKit is a $99 GitHub repo that contains a template for everything you need
UX
The authors of Elicit propose that LLM UX should resemble a living documents
editable results table is secretly a big-batch workload manager in the browser.
OpenUI Github Describe your UI and have it rendered live. “You can ask for changes and convert HTML to React, Svelte, Web Components, etc. It’s like v0 but open source and not as polished”:

Code Editing
Meta Code Llama is an LLM optimized for coding.
llama.cpp will run using 4-bit integer quantization on a MacBook.
The Manifesto outlines the project to make local LLMs.
Google launches Project IDX an AI-enabled browser-based development environment for building full-stack web and multiplatform apps.
Stability AI and StableCode
- based on BigCode
- long-context-window version has a context window of 16,000 tokens
- Rather than using the ALiBi (Attention with Linear Biases) approach to position outputs in a transformer model — the approach used by StarCoder for its open generative AI model for coding — StableCode is using an approach known as rotary position embedding (RoPE).
see HN for mixed reviews.

Lets you ask coding questions with a 6000 character limit.
Upgraded to Phind-70B CodeLlama-70B model and is fine-tuned on an additional 50 billion tokens, yielding significant improvements. It also supports a context window of 32K tokens.
available to try for free and without a login.
Cursor: The AI-first Code Editor: Build software faster in an editor designed for pair-programming with AI. (formerly cursor.so)
Free version is 2000 completions, 50 slow requests Pro is $20/month for unlimited
Search
LLocalSearch is a LLama-based model that runs on locally on your laptop (no OpenAI API calls needed). It uses regular search engine calls to augment the local LLM.
Vector Databases

Pinecone is a vector search platform.

LanceDB is an open-source database for vector-search built with persistent storage, which greatly simplifies retrevial, filtering and management of embeddings.
The key features of LanceDB include:
Production-scale vector search with no servers to manage.
Store, query and filter vectors, metadata and multi-modal data (text, images, videos, point clouds, and more).
Support for vector similarity search, full-text search and SQL.
Native Python and Javascript/Typescript support.
Zero-copy, automatic versioning, manage versions of your data without needing extra infrastructure.
Ecosystem integrations with LangChain 🦜️🔗, LlamaIndex 🦙, Apache-Arrow, Pandas, Polars, DuckDB and more on the way.
LanceDB’s core is written in Rust 🦀 and is built using Lance, an open-source columnar format designed for performant ML workloads.
Zilliz is a web-hosted version of the open source Milvus


Chroma: the AI-native open-source embedding database is integrated with PaLM embeddings.
Also see Vespa, Qdrant, Supabase, Chroma and this tweet
Learn how to use vector embeddings using pgvector (see HN)
Optimization
Code optimization: FrugalGPT is a framework proposed by Lingjiao Chen, Matei Zaharia and James Zou from Stanford University in their 2023 paper “FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance”. The paper outlines strategies for more cost-effective and performant usage of large language model (LLM) APIs.
The core of FrugalGPT revolves around three key techniques for reducing LLM inference costs:
- Prompt Adaptation - Using concise, optimized prompts to minimize prompt processing costs
- LLM Approximation - Utilizing caches and model fine-tuning to avoid repeated queries to expensive models
- LLM Cascade - Dynamically selecting the optimal set of LLMs to query based on the input
Groq, which claims to be a 10x faster Language Processing Unit™ based inference engine that supports PyTorch, TensorFlow, and ONNX for inference. They claim to beat any price / million inferences.
Issues
Vicki Boykis: What we don’t talk about when we talk about building AI apps a summary of some engineering issues, like how to handle the large Docker files, and build times.
Dan Shipper’s observations after using Github CoPilot Workspace , similar to Devin that lets you develop an entire software program in plain English. The biggest problem of course is that the model has to make lots of assumptions about what you mean, since part of software development involves the discipline of precisely articulating tasks that aren’t necessarily obvious.
Security
Bar Lanyado, security researcher at Lasso Security noticed that AI coding assistants often reference non-existent packages. He created one called huggingface-CLI and uploaded it to the Python Package Index (PyPI), getting 15,000 downloads of his (potentially malicious) code. Read details at AI hallucinates software packages and devs download them – even if potentially poisoned with malware
see
LLM Decompiling
The LLM4Decompile project is building large language models for decompiling software (translating from assembly back into a higher level language like C). This would be a tremendous tool for reverse engineering. The models are available on Hugging Face.
Meta: Meta Large Language Model Compiler: Foundation Models of Compiler Optimization
we introduce Meta Large Language Model Compiler (LLM Compiler), a suite of robust, openly available, pre-trained models specifically designed for code optimization tasks.
We also present fine-tuned versions of the model, demonstrating its enhanced capabilities in optimizing code size and disassembling from x86_64 and ARM assembly back into LLVM-IR. These achieve 77% of the optimising potential of an autotuning search, and 45% disassembly round trip (14% exact match).
GPU Programming
Jeremy Howard has a video on getting started with CUDA programming (NVIDIA GPU programming). It is aimed at Python programmers but no doubt useful for almost anyone.
Developers and what they’re up to